Research paper
Blog post
GitHub repository
Introduction
We introduce the Pathways Language and Image (PaLI) model, a scalable approach to joint modeling of language and images that reaches new levels of performance in multiple vision-language tasks and multiple languages.PaLI leverages the increased understanding capabilities unlocked by scaling the image and language unimodal components, benefitting especially from scaling up the vision backbone to a 4B parameter Vision Transformer (ViT). PaLI saves compute and resources by using these unimodal pre-trained models.
We also introduce the WebLI dataset, which includes 10 billion image-text pairs from 109 languages, and enables vision-language capabilities in many languages when paired with large-capacity models.
PaLI uses the same API (input: image + text; output: text) to solve multiple vision-language tasks, across many languages. These tasks include image-language, image-only, and language-only tasks, such as visual question answering, image captioning, classification, OCR, text reasoning and others.
In experiments, we observe that the PaLI model:
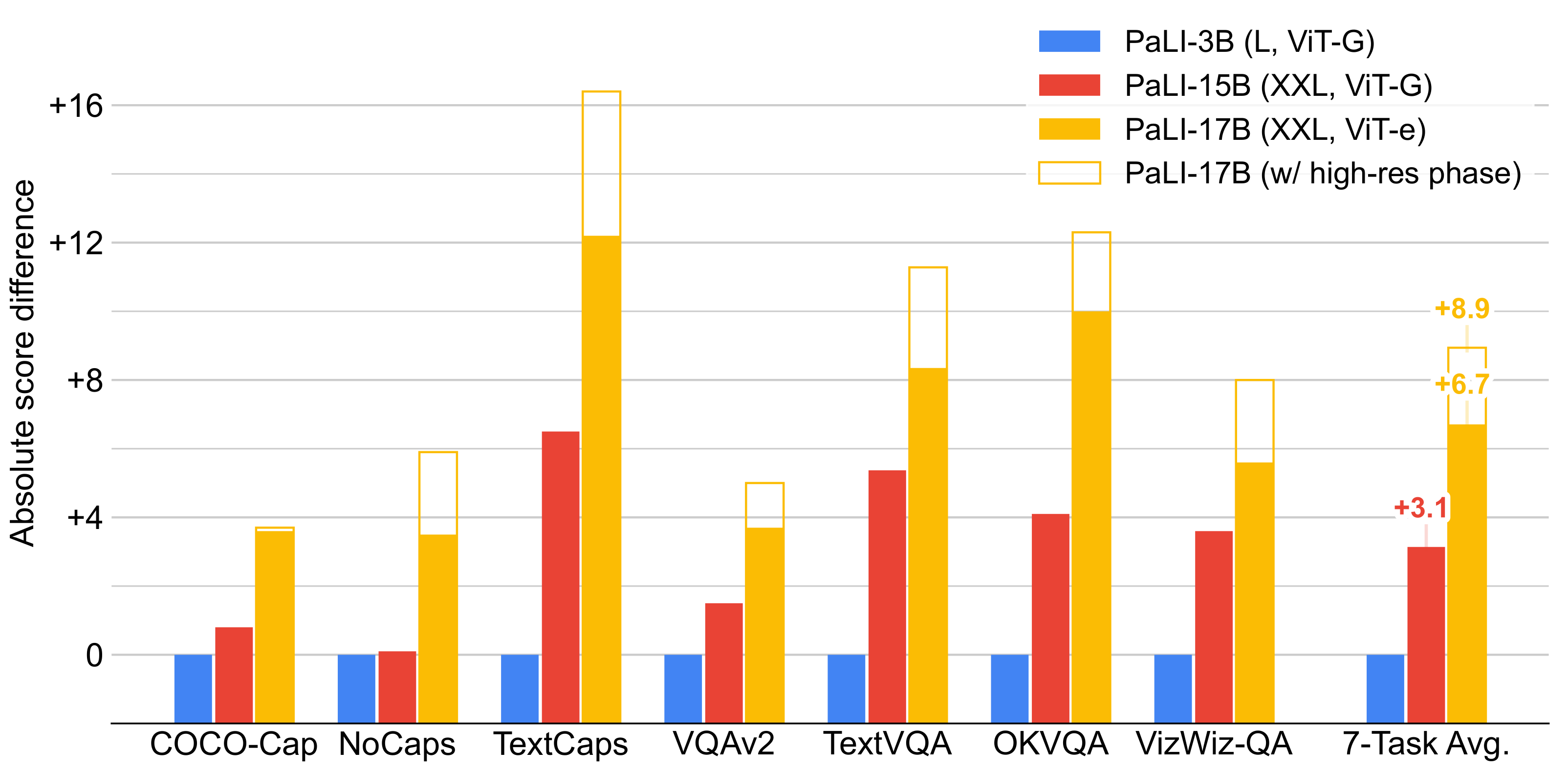
- Achieves state-of-the-art performance, or better, on challenging image captioning and visual question answering benchmarks, including COCO-Captions, nocaps, TextCaps, VQAv2, OK-VQA, TextVQA, and VizWiz-QA
- Exceeds prior models’ performance on multilingual visual captioning benchmarks, as well as on multilingual visual question answering benchmarks xGQA and MaXM.
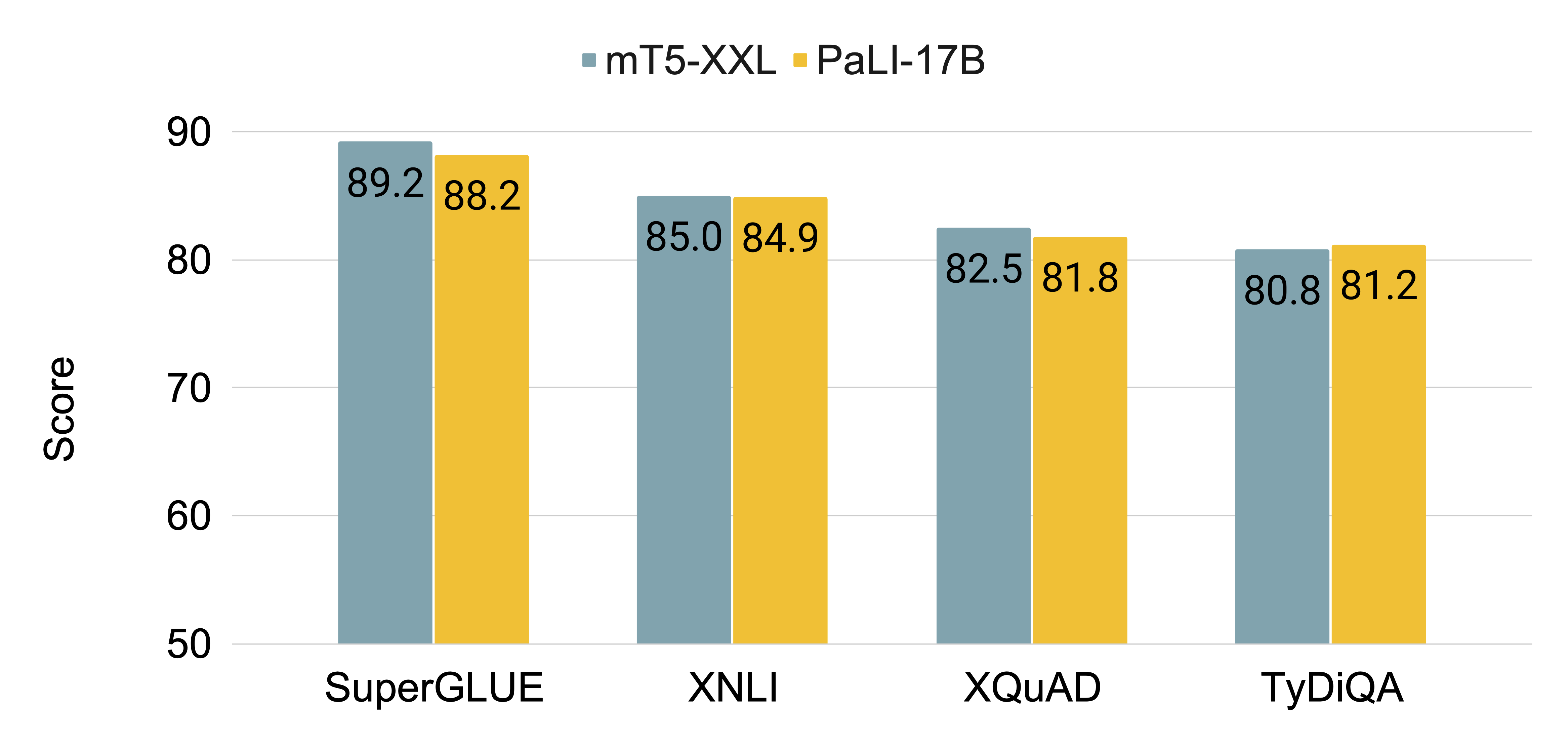
- Retains or improves capabilities on pure vision tasks, such as image classification, and in pure language tasks, such as question-answering and natural language inference.
|
|
PaLI is a simple, reusable and scalable architecture based on Transformer Encoders, including a Visual Transformer (ViT), a Multimodal Encoder and a Text Decoder. It can reuse previously trained models (mT5, ViT), and it is trained on WebLI to perform a wide range of tasks in the image-only, language-only, and image-language domains (e.g., visual-question answering, image captioning, scene-text understanding, etc.).
|