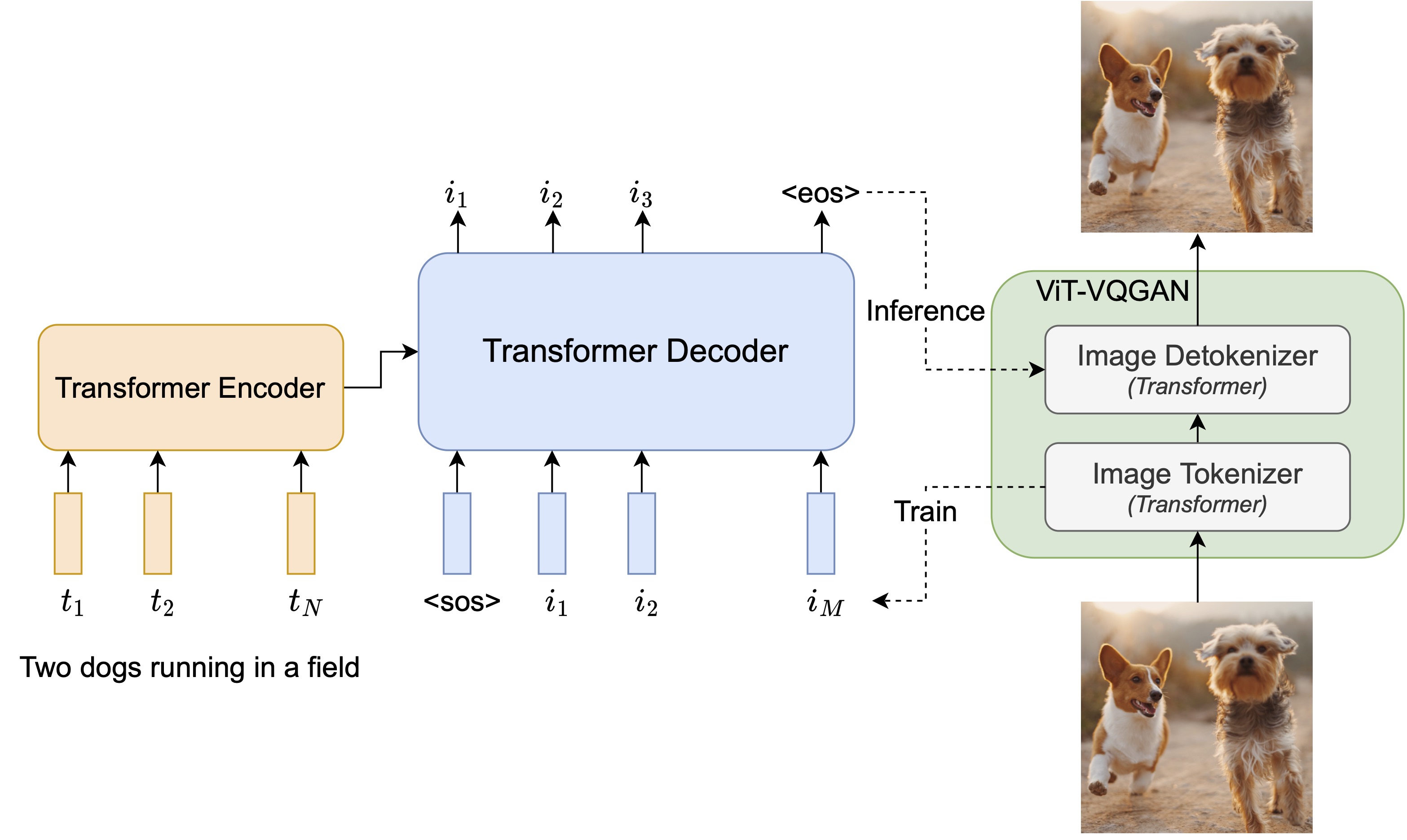
Responsibility and broader impact
As we discuss at greater length in the paper, text-to-image models introduce many opportunities and risks, with potential impact on bias and safety, visual communication, disinformation, and creativity and art. Similar to
Imagen,
we recognize there is a risk that Parti may encode harmful stereotypes and representations. Some potential risks relate to the way in which the models are themselves developed, and this is especially true for the training data. Current models like Parti are trained on large, often noisy, image-text datasets that are known to contain biases regarding people of different backgrounds. This leads such models, including Parti, to produce stereotypical representations of, for example, people described as lawyers, flight attendants, homemakers, and so on, and to reflect Western biases for events such as weddings. This presents particular problems for people whose backgrounds and interests are not well represented in the data and the model, especially if such models are applied to uses such as visual communication, e.g. to help low-literacy social groups. Models which produce photorealistic outputs, especially of people, pose additional risks and concerns around the creation of deepfakes. This creates risks with respect to the possible propagation of visually-oriented misinformation, and for individuals and entities whose likenesses are included or referenced.
Text-to-image models open up many new possibilities for people to create unique and aesthetically pleasing images – essentially, acting as a paint brush to enhance human creativity and productivity. However, in assessing design or artistic merit, it is important to have
a nuanced understanding of algorithmically based art
over the years, the model itself, the people involved and the broader artistic milieu. Bias also matters here, as the range of outputs from a model is dependent on the training data, and this may have biases toward Western imagery and further prevent models from exhibiting radically new artistic styles – the way human artists can.
For these reasons, we have decided not to release our Parti models, code, or data for public use without further safeguards in place. In the meantime, we provide a Parti watermark on all images that we release. We will focus on following this work with further careful model bias measurement and mitigation strategies, such as prompt filtering, output filtering, and model recalibration. We believe it may be possible to use text-to-image generation models to understand biases in large image-text datasets at scale, by explicitly probing them for a suite of known bias types, and potentially uncovering other forms of hidden bias. We also plan to coordinate with artists to adapt high-performing text-to-image generation models’ capabilities to their work. This is especially important given the intense interest among many research groups, and the rapid development of models and data to train them. Ideally, we hope these models will augment human creativity and productivity, not replace it, so that we can all enjoy a world filled with new, varied, and responsible aesthetic visual experiences.
Data card
Acknowledgements
Parti is a collaboration that spans authors across multiple Google Research teams:
Jiahui Yu*,
Yuanzhong Xu†,
Jing Yu Koh†,
Thang Luong†,
Gunjan Baid†,
Zirui Wang†,
Vijay Vasudevan†,
Alexander Ku†
Yinfei Yang,
Burcu Karagol Ayan,
Ben Hutchinson,
Wei Han,
Zarana Parekh,
Xin Li,
Han Zhang
Jason Baldridge†,
Yonghui Wu*
*Equal contribution
†Core contribution
We would like to thank Elizabeth Adkison, Fred Alcober, Tania Bedrax-Weiss, Krishna Bharat, Nicole Brichtova, Yuan Cao, William Chan, Zhifeng Chen, Eli Collins, Claire Cui, Andrew Dai, Jeff Dean, Emily Denton, Toju Duke, Dumitru Erhan, Brian Gabriel, Zoubin Ghahramani, Jonathan Ho, Michael Jones, Sarah Laszlo, Quoc Le, Lala Li, Zhen Li, Sara Mahdavi, Kathy Meier-Hellstern, Kevin Murphy, Paul Natsev, Paul Nicholas, Mohammad Norouzi, Niki Parmar, Ruoming Pang, Fernando Pereira, Slav Petrov, Vinodkumar Prabhakaran, Utsav Prabhu, Evan Rapoport, Keran Rong, Negar Rostamzadeh, Chitwan Saharia, Gia Soles, Austin Tarango, Ashish Vaswani, Tao Wang, Tris Warkentin, Austin Waters, Ben Zevenbergen for helpful discussions and guidance, Peter Anderson, Corinna Cortes, Tom Duerig, Douglas Eck, David Ha, Radu Soricut and Rahul Sukthankar for paper review and feedback, Erica Moreira and Victor Gomes for help with resource coordination, Tom Small for designing the Parti watermark, Google ML Data Operations team for collecting human evaluations on our generated images and others in the Google Brain team and Google Research team for support throughout this project.
We would also like to give particular acknowledgments to the Imagen team, especially Mohammad Norouzi, Chitwan Saharia, Jonathan Ho and William Chan, for sharing their near complete results prior to releasing Imagen; their findings on the importance of CF guidance were particularly helpful for the final Parti model. We also thank the Make-a-Scene team, especially Oran Gafni, for helpful discussion on CF-guidance implementation in autoregressive models. We thank the DALL-E 2 authors, especially Aditya Ramesh, for helpful discussion on MS-COCO evaluation. We also thank the DALL-Eval authors, especially Jaemin Cho, for help with reproducing their numbers.