Research paper
Request API Access
Universal Speech Model (USM) is a family of state-of-the-art speech models with 2B parameters trained on 12 million hours of speech and 28 billion sentences of text, spanning 300+ languages. USM, which is for use in YouTube (e.g., for closed captions), can perform automatic speech recognition (ASR) on widely-spoken languages like English and Mandarin, but also languages like Punjabi, Assamese, Santhali, Balinese, Shona, Malagasy, Luganda, Luo, Bambara, Soga, Maninka, Xhosa, Akan, Lingala, Chichewa, Nkore, Nzema to name a few. Some of these languages are spoken by fewer than twenty million people, making it very hard to find the necessary training data.
We demonstrate that utilizing a large unlabeled multilingual dataset to pre-train the encoder of our model and fine-tuning on a smaller set of labeled data enables us to recognize these under-represented languages. Moreover, our model training process is effective for adapting to new languages and data.
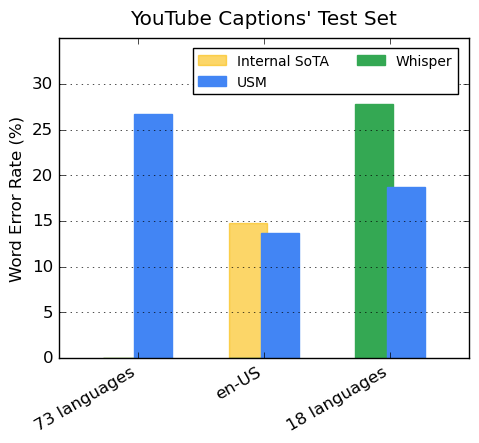
Our encoder incorporates 300+ languages through pre-training. We demonstrate the effectiveness
of the pre-trained encoder through fine-tuning on YouTube Caption's multilingual speech data. The
supervised YouTube data includes 73 languages and has on average less than three thousand
hours of data per language. Despite limited supervised data, the model achieves less
than 30% word error rate (WER; lower is better) on average across the 73 languages,
a milestone we have never achieved before. For en-US, USM has a 6% relative lower WER
compared to the current internal state-of-the-art model. Lastly, we compare with the
recently released large model, Whisper (large-v2),
which was trained with more than 400k hours of labeled data. For the comparison, we only use the 18 languages
that Whisper can successfully decode with lower than 40% WER. Our model has,
on average, a 32.7% relative lower WER compared to Whisper for these 18 languages.
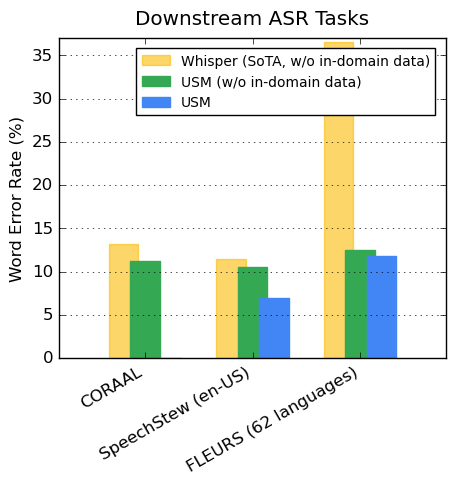
On publically available datasets, our model shows lower WER compared to Whisper on CORAAL
(African American Vernacular English), SpeechStew
(English), and FLEURS (102 languages).
Our model achieves lower WER with and without training on in-domain data. The
comparison on FLEURS reports the subset of languages (62) that overlaps with the languages
supported by the Whisper model. For FLEURS, USM without in-domain data has a 65.8% relative
lower WER compared to Whisper and has a 67.8% relative lower WER with in-domain data.
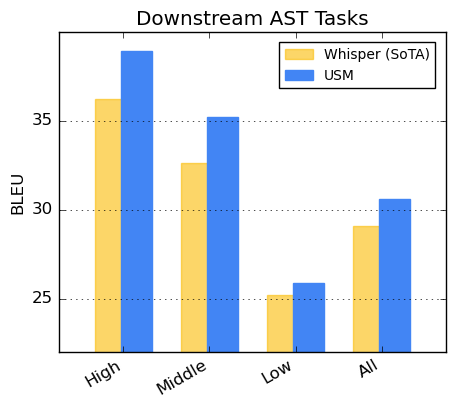
For speech translation, we fine-tune USM on the
CoVoST dataset. We segment the languages into high, medium, and low based on
resource availability and calculate the BLEU
score for each segment. As shown, USM outperforms Whisper for all
segments. Higher is better for BLEU.
We thank all the co-authors for contributing to the project and paper including
Andrew Rosenberg, Ankur Bapna, Bhuvana Ramabhadran, Bo Li, Chung-Cheng Chiu, Daniel Park,
Françoise Beaufays, Gary Wang, Ginger Perng, James Qin, Jason Riesa, Johan Schalkwyk,
Ke Hu, Nanxin Chen, Parisa Haghani, Pedro Moreno Mengibar, Rohit Prabhavalkar, Tara Sainath,
Trevor Strohman, Vera Axelrod, Wei Han, Yonghui Wu, Yongqiang Wang, Yu Zhang,
Zhehuai Chen, and Zhong Meng.
We also thank Alexis Conneau, Min Ma, Shikhar Bharadwaj, Sid Dalmia, Jiahui Yu,
Jian Cheng, Paul Rubenstein, Ye Jia, Justin Snyder, Vincent Tsang, Yuanzhong Xu,
Tao Wang for useful discussions.
We appreciate valuable feedback and support from Eli Collins, Jeff Dean, Sissie Hsiao,
Zoubin Ghahramani. Special thanks to Austin Tarango, Lara Tumeh, Amna Latif, and Jason Porta
for their guidance around responsible AI practices. We thank Elizabeth Adkison,
James Cokerille for help with naming the model, Abhishek Bapna for editorial support, and Erica Moreira for resource management.
We also thank Anusha Ramesh for feedback, guidance, and assisting with the publication
strategy, and Calum Barnes and Salem Haykal for their valuable partnership.
We thank the Parti Team for developing the template for this site.
2023.03.06