Overview
Weather forecasting using machine learning (ML) has seen rapid progress in recent years. WeatherBench is an open framework for evaluating ML and physics-based weather forecasting models in a like-for-like fashion.
This website contains up-to-date scores of many state-of-the-art global weather models with a focus on medium-range (1-15 day) prediction. In addition, the WeatherBench framework consists of our recently updated WeatherBench-X evaluation code and publicly available, cloud-optimized ground-truth and baseline datasets, including a comprehensive copy of the ERA5 dataset used for training most ML models. For more information on how to use the WeatherBench evaluation framework and how to add new models to the benchmark, please check out the documentation.
The research community can file a GitHub issue to share ideas and suggestions directly with the WeatherBench 2 team.
Headline scorecards
There is no single metric for measuring weather forecast performance. For example, one end user might be worried about wind gusts, while another might care more about average temperatures. For this reason, WeatherBench 2 contains a range of metrics, which you can find in the navigation at the top of this page. To provide a concise summary, we defined several key - “headline” - metrics that closely mirror the routine evaluation done by weather agencies and the World Meteorological Organization. It is important to remember that these metrics measure some important but not all aspects of what makes a good forecast.
The scorecards below show the skill (measured by the global root mean squared error) of different physical and ML-based methods relative to ECMWF's IFS HRES, one of the world's best operational weather models, on a number of key variables. For a detailed explanation of the different skill metrics and variables, check out the FAQ.
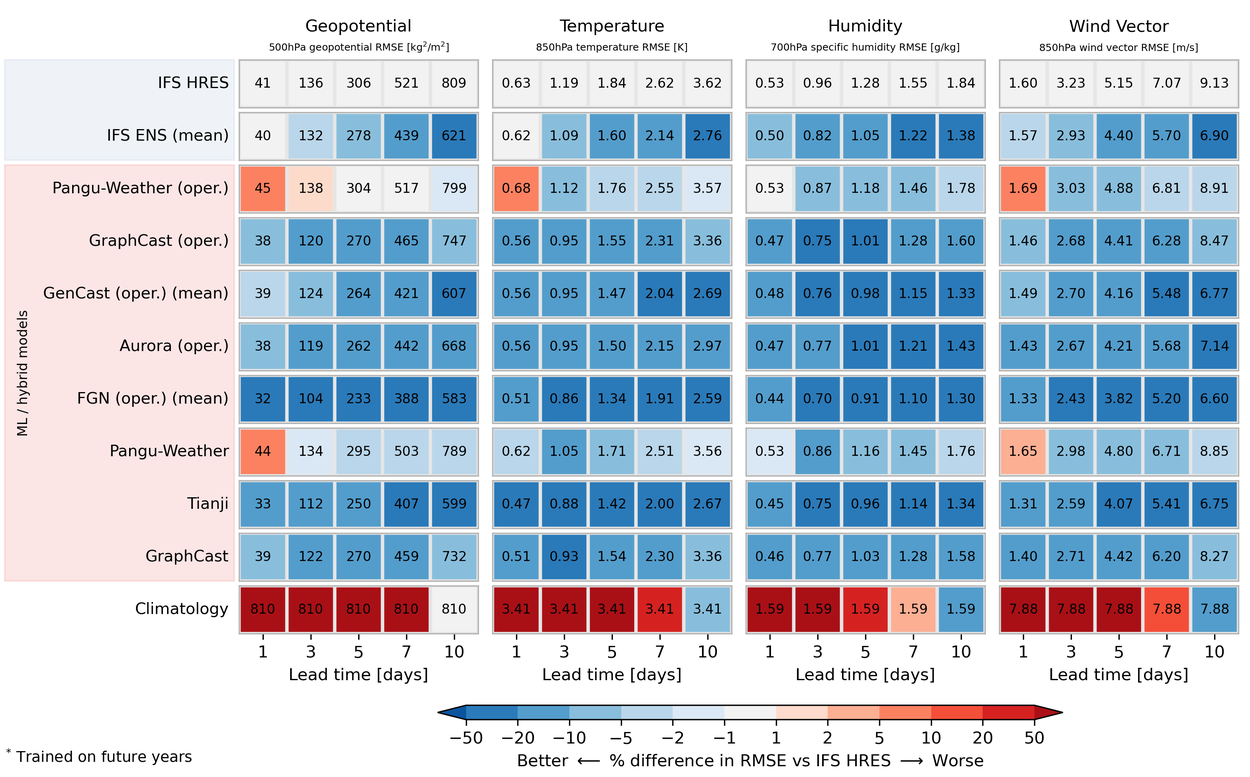
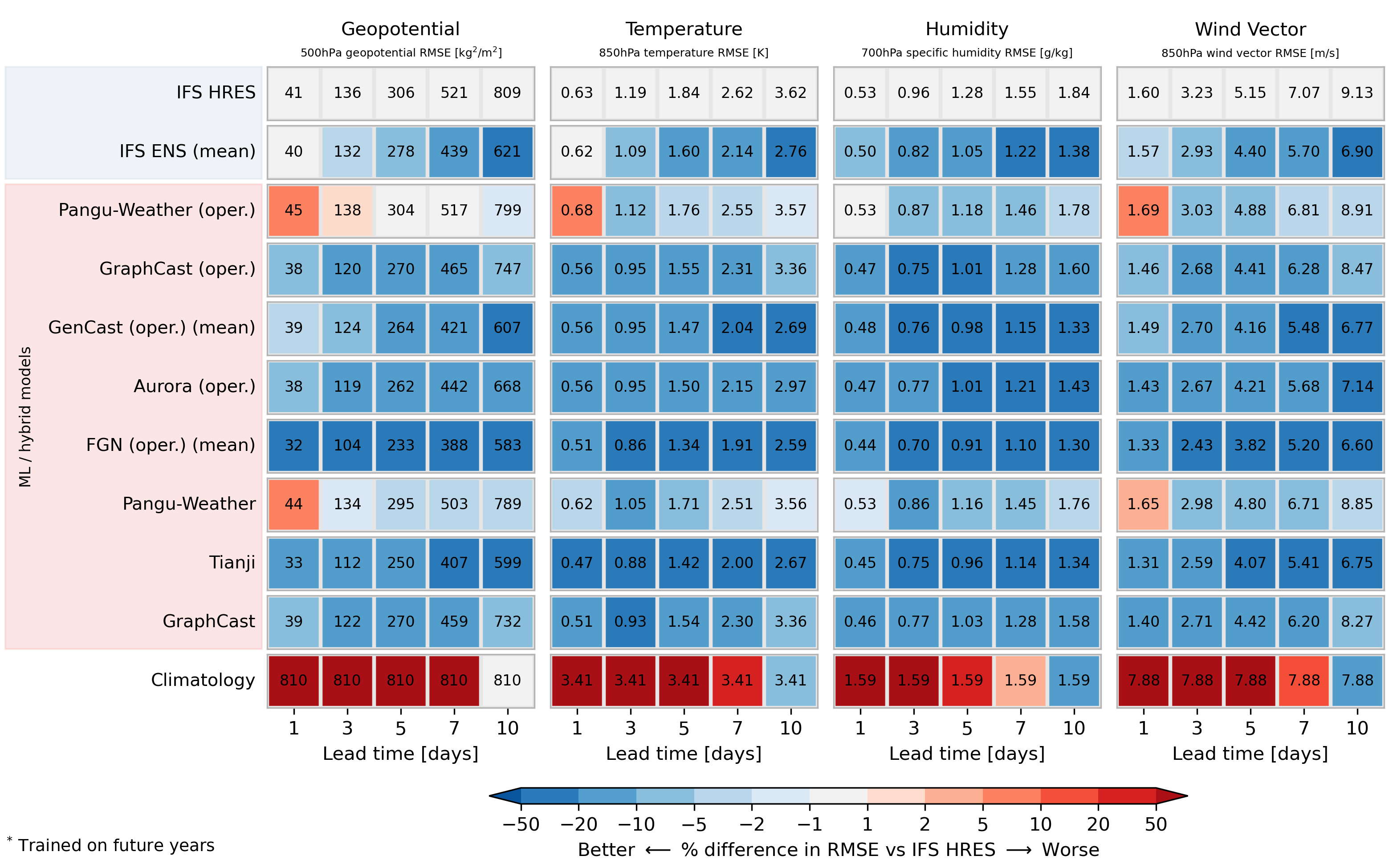
Scorecard for upper-level variables for the year 2022. Operational models are evaluated against IFS analysis. All other models evaluated against ERA5. Order of ML models reflects publication date. For more detail, visit Deterministic Scores.
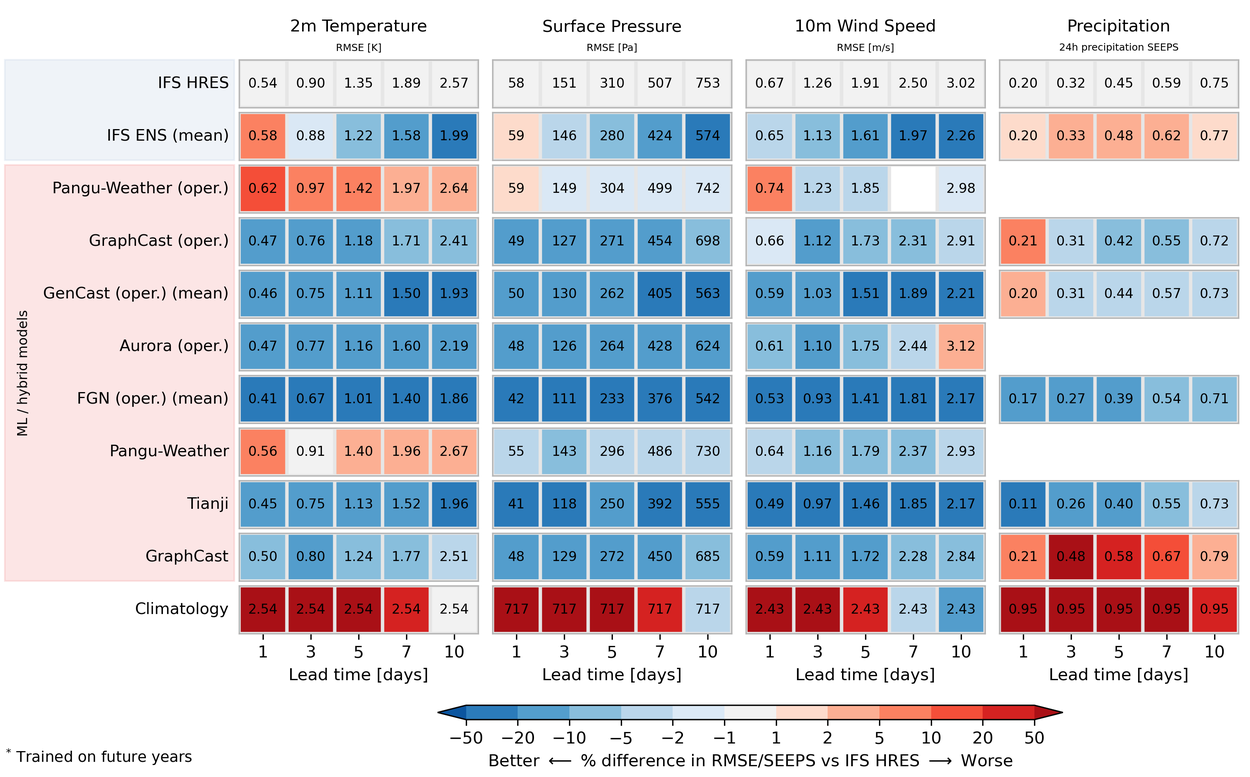
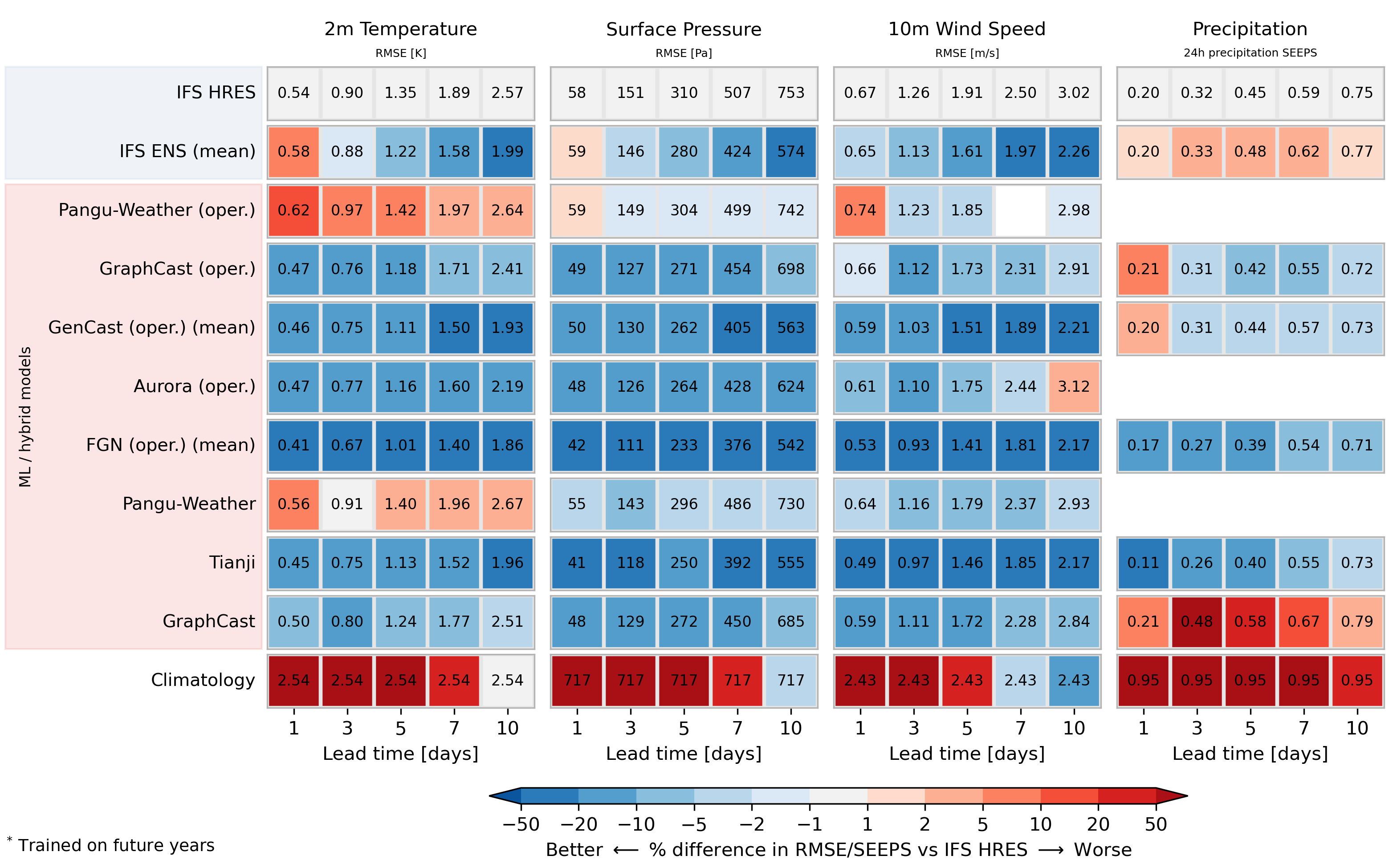
Scorecard for surface variables for the year 2022. Operational models are evaluated against IFS analysis. All other models evaluated against ERA5. Order of ML models reflects publication date. Precipitation is evaluated using the SEEPS score using ERA5 ground truth for all models. For more detail, visit Deterministic Scores. See FAQ for details on how climatology is computed.
Probabilistic scorecards
The scorecard below shows the skill (measured by the continuous ranked probability score = CRPS) of physical and ML-based probabilistic models, relative to ECMWF's IFS ENS model.
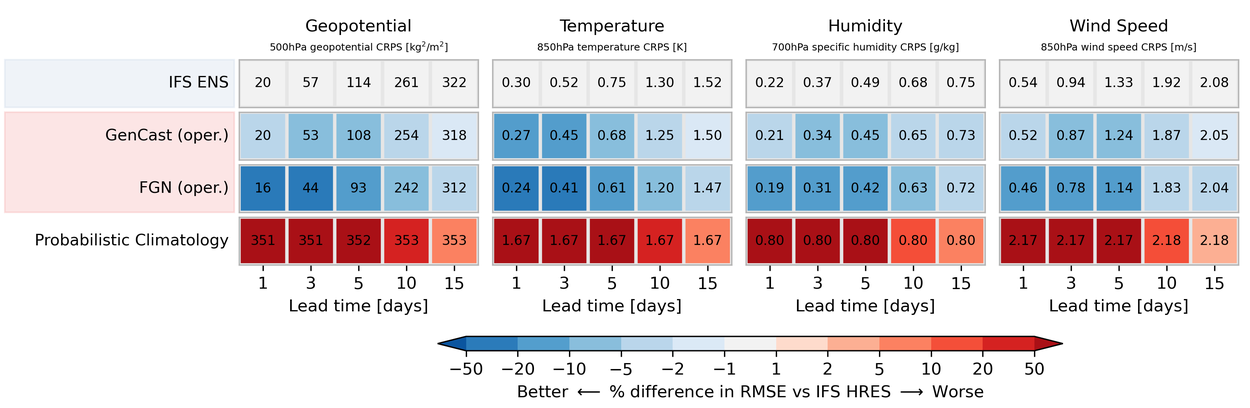
Probabilistic scorecard for upper-level variables for the year 2022. Operational models (blue) are evaluated against IFS analysis. All other models evaluated against ERA5. Order of ML models reflects publication date. For more detail, visit Probabilistic Scores.
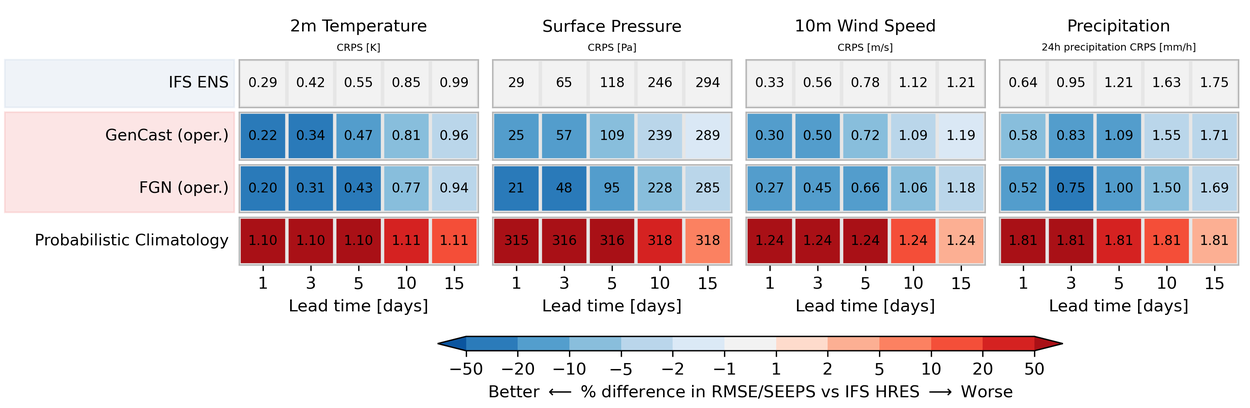
Probabilistic scorecard for surface variables for the year 2022. Operational models (blue) are evaluated against IFS analysis. All other models evaluated against ERA5. Order of ML models reflects publication date. For more detail, visit Probabilistic Scores.
Participating models
Missing an existing model or have a new model that you'd like to see added? Check out this guide for how to participate or submit a GitHub issue. Please also refer to the FAQ for more detailed information.
|
Model / Dataset |
Source |
Method |
Type |
Initial conditions |
Horizontal resolution ** |
|---|---|---|---|---|---|
|
ECMWF |
Physics-based |
Reanalysis |
|
0.25° |
|
|
ECMWF |
Physics-based |
Forecast (deterministic) |
Operational |
0.1° |
|
|
ECMWF |
Physics-based |
Forecast (50 member ensemble) |
Operational |
0.2° * |
|
|
Pangu-Weather (operational) |
Huawei |
ML-based |
Forecast (deterministic) |
Operational IFS |
0.25° |
|
GraphCast (operational) |
Google DeepMind |
ML-based |
Forecast (deterministic) |
Operational IFS |
0.25° |
|
ECMWF |
Physics-based |
Hindcast (deterministic) |
ERA5 |
0.25° |
|
|
Ryan Keisler |
ML-based |
Forecast (deterministic) |
ERA5 |
1° |
|
|
Huawei |
ML-based |
Forecast (deterministic) |
ERA5 |
0.25° |
|
|
Google DeepMind |
ML-based |
Forecast (deterministic) |
ERA5 |
0.25° |
|
|
Fudan University, Shanghai |
ML-based |
Forecast (deterministic) |
ERA5 |
0.25° |
|
|
Google Research |
ML-based |
Forecast (deterministic) |
ERA5 |
1.4x0.7° |
|
|
Google Research |
Hybrid |
Forecast (deterministic) |
ERA5 |
0.7° |
|
|
Google Research |
Hybrid |
Forecast (Ensemble) |
ERA5 |
1.4° |
|
|
Google DeepMind |
ML-based |
Forecast (Ensemble) |
ERA5 |
0.25° |
|
|
UCLA et al. |
ML-based |
Forecast (Ensemble) |
ERA5 |
1.4° |
|
|
Excarta |
ML-based |
Forecast (deterministic) |
ERA5 |
0.25° |
|
|
Inria et al. |
ML-based |
Forecast (deterministic) |
ERA5 |
1.5° |
|
|
Inria et al. |
ML-based |
Forecast (Ensemble) |
ERA5 |
1.5° |
|
|
DAMO Academy, Alibaba Group |
ML-based |
Forecast (deterministic) |
ERA5 |
0.25° |
|
|
WeatherMesh 4 *** |
WindBorne |
ML-based |
Forecast (deterministic) |
ERA5 |
0.25° |
|
Microsoft Research |
ML-based |
Forecast (deterministic) |
Operational IFS |
0.25° |
|
|
Google DeepMind |
ML-based |
Forecast (Ensemble) |
Operational IFS |
0.25° |
|
|
Envision Group |
ML-based |
Forecast (deterministic) |
ERA5 |
0.25° |
* Since June 2023, IFS ENS is also run at 0.1° resolution.

Probabilistic scorecard for surface variables for the year 2022. Operational models (blue) are evaluated against IFS analysis. All other models evaluated against ERA5. Order of ML models reflects publication date. For more detail, visit Probabilistic Scores.